When I first approached I was excited to see that package management was part of the toolchain. When I first ran go get I was excited at how simple it was. Very quickly I was off and running with 3rd party packages.
But, then it happened. I wanted something more than fetching packages. I wanted to manage them for an application. I quickly learned there was a gap here. I learned I wasn’t the only one. Just look at the wiki listing some of the tools.
It’s not just the wide variety of tools that have entered this space. One of the biggest topics of conversations at meetups, in backchannels, and those “parking lot conversations” is package management.
Oh, and I know numerous people who looked at Go or tried it for a bit and walked away because of the state of package management. It’s a barrier to entry and a pain point.
We need to solve this.
Where To Begin?
Cars have a common driving experience. If you drive a car from Ford, GM, Toyota, Tesla, or someone else you’ll find the main controls are the same. Even the custom bits are common enough it’s easy to intuitively pick them up. This even extends to cars with different power trains. When electric cars came out the controls weren’t some new thing. In fact, Tesla has gotten accolades for their driving experience while keeping the same controls.
If you ever travel and have to rent a car you see what this means in action. You can show up at a rental car place, get a car without worrying about the manufacturer or model, get in, and drive within seconds.
Cars are great but how does this apply to package management? Package management isn’t a new space. CPAN was conceived back in 1993 and has been online for over 20 years. Since then Java, Python, PHP, Ruby, JavaScript, Rust, .NET (I know it’s a platform but whatever), and numerous others have all solved package management. Amazingly, they did it following similar patterns. It turns out that if you know how to drive one of these package managers you can easily pickup and drive one in another language. There is so much similarity.
That’s what Go needs. Package management that someone coming from another language can just pickup and drive without much thinking.
But, but, but, Go is a unicorn
On numerous occasions I’ve been told that Go is a unicorn and shouldn’t do package management like other languages. Go does many fantastic things. The way goroutines, channels, error handling, and numerous other things work is great. But, does that make Go a unicorn?
Personally, I think package management in Go is making it a unicorn in a bad way.
Developers want to be productive in a programming language. Go has a lot of that built into the language and toolchain. But, package management has lots of feature gaps, feels foreign, and simply doesn’t compare to what’s offered by other languages.
Package management needs to enable developers where they are, make package management simple, and get out of the way.
We need to fix this.
So, what does this look like?
Now comes the uncomfortable part. We need to talk about what this means. We need to look at the warts.
Release Versions
Let’s take a poll. Who’s running Go version 7555f7f2bf1636443b6013c90e45698894af75e1? Anyone? It’s unlikely any production code is running that version of Go. Instead we all use release versions like 1.5.3 or 1.6. These versions have been tested, documented, and are intended for release. They are release versions.
In most languages everything that’s distributed has released versions. Libraries and applications have releases. Most recently the commonalities have formed into semantic versioning where the parts of the version have meaning that can be read by a person and parsed by a machine.
Note, for those of you not familiar with semantic versioning it’s a specification and not just an idea. A spec you can build a spec compliant parser from.
But, if we know an interface fits isn’t that enough? Do versions really matter?
I hear questions like this all that time. Right now versions do matter because they communicate intent. Plus, you can have features and bugs sitting behind the same interface where the features and bugs matter. Right now we don’t have automation to deal with the difference.
For example, say we have the following function in a package:
func Parse(thing string) []string {
...
}
In different revisions there are difference such as:
- In revision 123 it parses things A, B, C.
- In revision 234 it parses things A, B, and C but has bug D.
- Revision 345 parses A, B, C, and E. Now bug D is gone.
In each case the the interface is the same. How do we transfer meaning from library author to consumer? A responsible library author will convey meaning with versions and other information.
Go needs versions. It’s blocking adoption of the language, hurting perception of Go, and causing lots of bad versions to be used.
Configuration Files
If you’ve heard about the vendor-spec, which is essentially a lock file, that’s not what I mean. You need a configuration file, sometimes called a manifest, and a lock file.
I can hear some of the questions now. Why do we need a configuration file? Can’t we pull everything from the source files? Why multiple files? These are legitimate questions so I’ll provide a few reasons.
- The languages that have more recently crafted package management tools. If you don’t see how that’s a reason go back to the example on driving a car.
- A manifest file and lock file have semantically different purposes. The manifest file contains information like the version ranges of a dependency that can be used (more on that in a moment). The lock file is a record of state at a point in time.
- Tools and process matter as well. Package management is automation to help people. A manifest file may not change very often. The lock file may not be used outside of releases or may be updated regularly. Some only lock down a codebase for releases. Or, looking at when changes occurred, what was changed, and what that means is easier when changes are attached to the semantic differences (separated by files here).
But, can’t we just tweak the import statement to have all the info we need? Take an application with hundreds of Go source files and numerous imports in each file. Now, append a version range and manage changes to it across all the files. And, make it easy for a person to read and understand let alone reduce work for automation tools.
Another common question is, aren’t different API versions supposed to live at different import paths in Go? This works great if you have a proprietary codebase, are using a monorepo, and don’t support the sharing culture of open source. And, it doesn’t address the issue of minor or patch versions.
Can you imagine that every time a library needs to increment a major version it needs to create a new repo on GitHub? Yeah, no one does that. The path for major API version is a Go thing. It’s not intuitive. Someone had to tell me. And, many Go developers just don’t do it. If they did there would be no reason for gopkg.in.
Configuration files in the form of a manifest file and lock file enable automation and the workflows that happen in practice.
Automation and Dependency Hell
Dependency Hell is a place. It has a Wikipedia page after all. So many who have worked with Go packages lament about being here. But, they don’t have to be.
Before we can talk about automation coming to the rescue we need to be aware of the problems. For example, diamond dependencies.
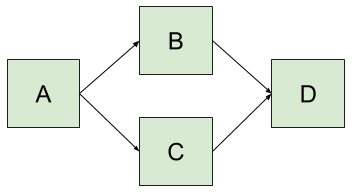
In this diagram:
- Package A depends on package B and C.
- Package B and C each depend on a different version of package D.
How do you resolve which version of D is good to use? There could be functional differences that matter aside from the functional API.
Some of you may be thinking that it’s a good idea for B and C to each use their own version. There are rare cases where you should do this. It’s just not the 80% case (see how all the other package managers do things). There are two Go consequences you should be aware of.
- Each version of the package will be in the resulting binary. If you do this by default you’ll quickly see binary bloat.
- Instances created from the package in one location aren’t compatible with the package in another location. So, no passing around loggers, database drivers, or any of that.
There is another way. Let your automation do it for you. If you specify compatible version ranges, such as with a semantic version range syntax, in your manifest files a package manager can walk the dependency tree, read the manifest files along the way, figure out the best version to use, and set all the versions up. Then it can take a snapshot to put into a lock file.
Turns out this is a solved problem. Rust (came out after Go), Python, Ruby, Java, PHP, and the other modern languages already do this. Yeah, even PHP has this nailed.
The diamond dependency problem is just one example.
Just The Start
This may seem highly opinionated and to a certain extent it is. This is open source and I’d like to see the most useful ideas be passed around. (Useful = Usability + Utility … you have to have both)
Plus, this is about simplicity. Solving package management problems by hand is a pain. Good automation can really help solve that and even help solve second order problems that most are unaware of.
This is just anteing up. If you look at the tooling in other languages it goes far beyond what’s outlined here.
Let’s ante up.
If you want to discuss this issue please feel free to join me working on Glide. A package manager that, like so many others in other language, tries to take the pain away. Or, by incorporating these ideas into other places. Or, maybe simply by tagging releases to your packages.
If you’re interested in more on this topic I recommend taking at look at “So you want to write a package manager”.