Kubernetes was birthed from tooling for on-premise data centers. So, it should be no surprise that it’s incredibly useful in on-premise situations like clusters. And, while the collective “we” often looks at the public cloud with Kubernetes, it’s worth looking at clusters in our offices, labs, and colocation data centers.
Borg And Google Data Centers
Kubernetes was birthed from the ideas of Borg and Omega at Google. There are even papers on it, such as Borg, Omega, and Kubernetes, from the people who worked on Borg and brought Kubernetes to life. If we look at the Borg architecture we can see it looks a lot like Kubernetes, especially in the early days.
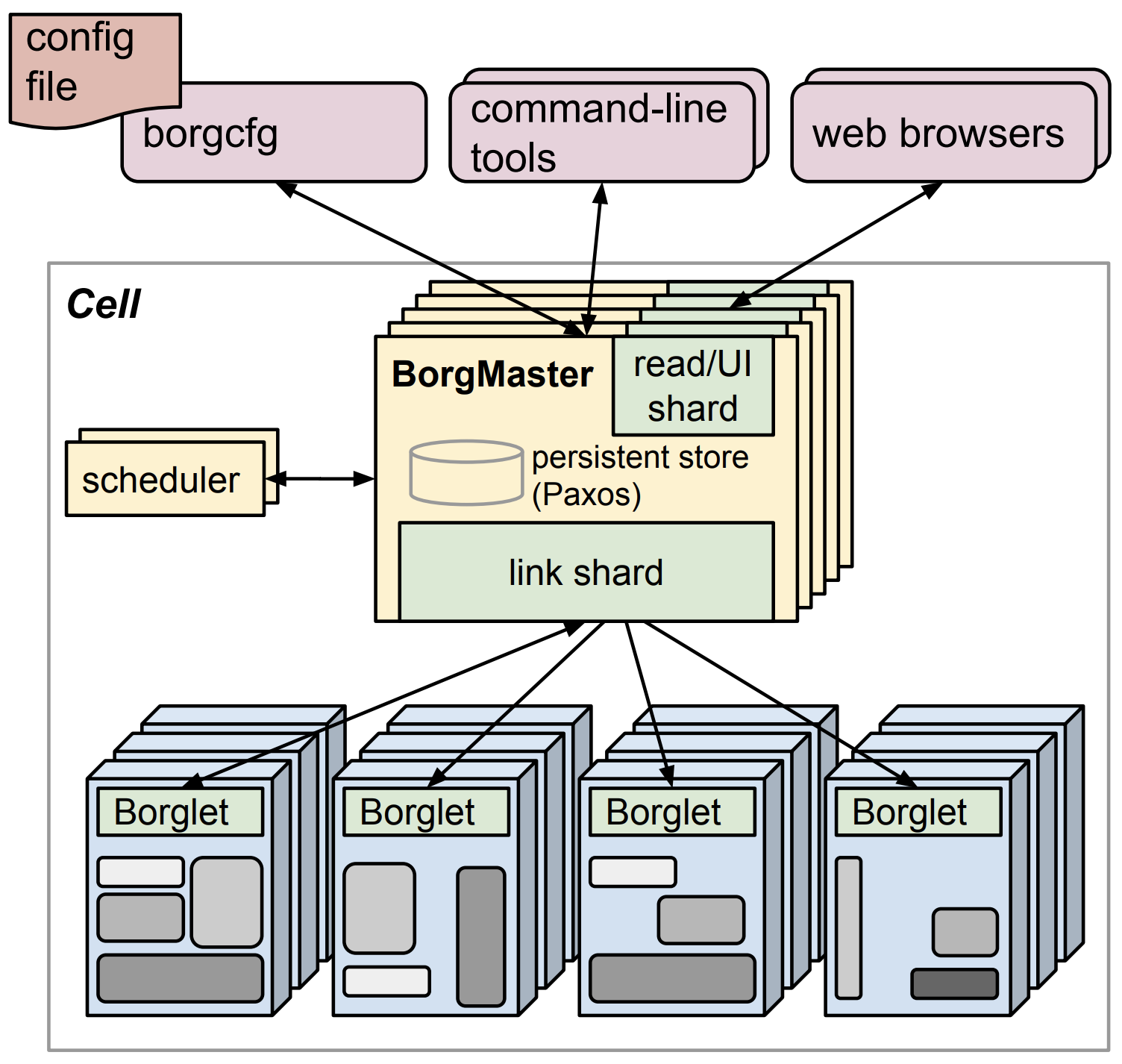 From the paper “Large-scale cluster management at Google with Borg”
From the paper “Large-scale cluster management at Google with Borg”
Borg, if you are unfamiliar with it, is Google’s data center operating system. You can read more about how they design their data centers in the book The Datacenter as a Computer: Designing Warehouse-Scale Machines. Borg isn’t the only piece of software in their stack, as they have customized so many things, but it is the piece that lets them run software on large clusters of custom made servers in a fault tolerant manner. And, it’s part of the stack that brings them amazing power usage effectiveness.
If Google uses the concepts we have in Kubernetes to run their own data centers, why shouldn’t we?
Why Kubernetes Is Useful
When I think of using Kubernetes for my own on-premise clusters, a couple of the many useful elements come to mind.
1. Fault Tolerance
Servers can be used for a long time. Their useful life for running many applications can be longer than 3 or 5 years that they may be expensed over. We can have servers that are 8 or even 10 years old doing useful work. But, what happens when those servers break or need to be replaced? Do the applications go offline?
If you’re using Kubernetes, the work that is on a server that fails can be re-scheduled onto a different server. I like to think of Kubernetes cluster as being one computer with hot swappable parts. This makes me feel safer using older machines that may be more likely to have failures that come with age.
2. Density
It’s not unusual for a server with a good utilization to only use 25% of the system resources. Not joking about this. The places that are on the high end may be 60%. When we divide our applications up by which machine they are on we don’t have a system to drive up utilization. And, it’s easy to get into a low utilization situation with far too many servers.
Kubernetes acting as a scheduler across the cluster means it can be more intelligent about scheduling and you can drive up utilization. Fewer servers can do more work.
Limitations
Of course, with any situation there are trade-offs and limitations. It’s worth considering some of those…
- Kubernetes has a limited ability to scale. Kubernetes has documentation for going up to 5,000 nodes in the cluster. At this level of scale you run into limitations, too. For example, the number of pods per node goes down. There are lots of technical reasons for this, like networking address space by default. Luckily, the mass majority of us don’t need scale in a single location. A cluster a fraction of this size works for most.
- The Kubernetes API is complicated. It’s been described as a platform for building platforms. Kubernetes sorta reminds of of Diego, the container scheduler behind Cloud Foundry (the platform in front). But, if you’re going to use terraform, ansible, or some other tool to manage what’s on your server you’re going to need to learn those details. Either way, you have something else to learn. And, it’s possible to be useful with Kubernetes quickly enough.
Conclusion
If you’re running a home lab, office/closet cluster of machines, something in a colo, or even beyond that Kubernetes is a useful option for on-premise.